Evaluation of Simulated Lake-Effect Zones and their Precipitation
View GLISA’s publication of this work (Coming Soon!)
GLISA is evaluating the representation of lake-effect zones (LEZs) in the Laurentian Great Lakes region and lake-effect precipitation in climate models to investigate whether a model simulates lake-effect precipitation, and if so, how well it is captured. We are using a data clustering approach (k-means clustering) to identify like “clusters” of seasonal precipitation amounts that tease out intense lake-effect and non-lake effect areas. We are using a Neighborhood Analysis method to compare LEZs in the models to observations to quantify the models’ spatial performance. We then calculate lake-effect precipitation biases to quantify errors in how much lake-effect precipitation is simulated by the models. Our focus is mainly on the winter climatology (1980-99) for the months of December, January, and February, since this is the historical period that overlaps in all our model simulations and winter lake-effects are most pronounced. We are applying our approach to the following climate model data sets:
- 19 dynamically downscaled simulations from the North-American Coordinated Regional Climate Downscaling Experiment (NA-CORDEX)
- 6 dynamically downscaled simulations from the UW-RegCM4 dataset
- CMIP5 was also considered but due to its coarse spatial resolution there are not enough data points within the base to run meaningful analysis
- HighRes-CMIP6 will be added to this analysis once available (anticipated late 2022)
- GLISA’s new dynamically downscaled projections using a 3-dimensional lake model will be added to this analysis once available
All model precipitation biases are being evaluated against the University of Delaware dataset from 1980-1999. All model data were downloaded as monthly data except for UW-RegCM4, which are daily data. More on GLISA’s methodology is available below.
Please contact GLISA at [email protected] with questions about this work.
Resources in this Project:

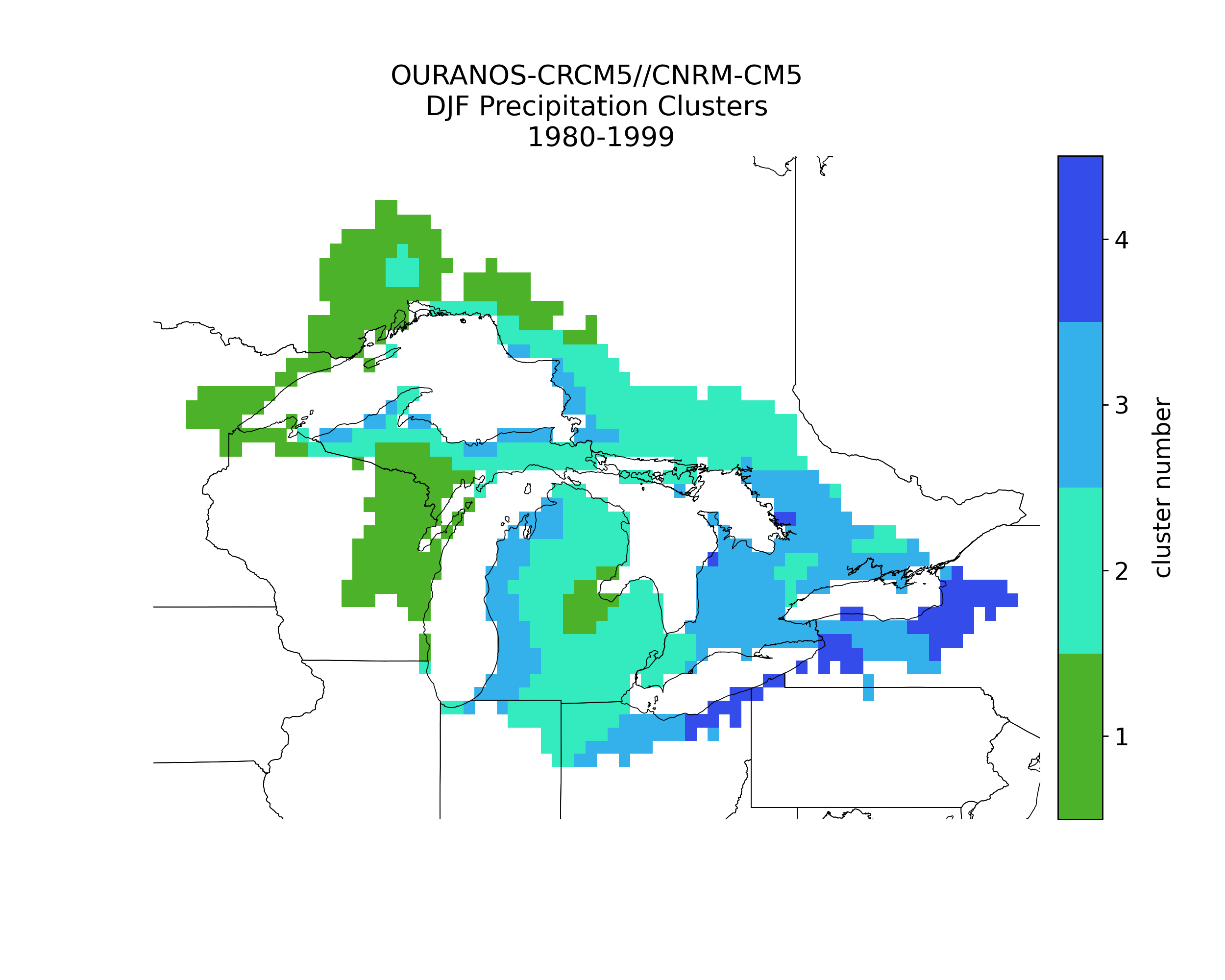
Fig 1. Precipitation clusters for the observational (University of Delaware) data using a k-means clustering algorithm where k=4. The results are clusters numbered 1-4, where 4 is the strongest lake effect precipitation cluster.
Research Methodology
We use a k-means clustering analysis to identify clusters of lake-effect precipitation and a neighborhood analysis to measure similarity (or dissimilarity) between lake-effect clusters in the model simulations and observations. Each cluster is formed with members having high similarity to each, in our case based on precipitation totals, compared to members of other clusters. Specifically, our use of k-means clustering partitions the precipitation data into a pre-specified number of groups. We explored up to 8 clusters and settled on four (Fig. 1), because with four clusters we could easily identify areas uninfluenced by the lakes (cluster #1), areas where the lakes have minimal influence (cluster #2), traditional lake-effect zones (cluster #3), and intense lake-effect zones (cluster #4). We use the MET tool to compare our lake-effect clusters in the models versus observations via a neighborhood analysis to know if the models get the lake-effect clusters in the right location and if they are of similar size. Lastly, we evaluate lake-effect precipitation biases by comparing precipitation totals in cluster 4 in the model simulations to the observations.
University of Delaware (UDEL) precipitation data was used as a historical observational data set due to its availability in both the U.S. and Canada and its gridded temporal resolution of 0.5º x 0.5º. The period 1980-1999 was used because this was the full length of years available in the UW-RegCM4, and we wanted to be able to compare biases across all model data sets. Winter (Dec-Jan-Feb) climatologies (20-year means) were calculated for total precipitation. Those 20-year means were then run through a k-means clustering program and the models’ clustering results were compared to the observational clustering results. The spatial domain omits data over the Great Lakes (because precipitation observations are not widely available) and only includes data in the Great Lakes watershed. Initially we included locations farther outside of the watershed, but intense precipitation in the mountainous regions of PA and NY affected the way the lake-effect clusters were drawn.
A more detailed description of our methodology is available in a forthcoming paper.
Simulated Lake-Effect Zones
The following are examples of how the models partition precipitation into lake-effect and non-lake-affect areas. Cluster #1 is associated with the lowest amounts of precipitation, or non-lake-effect regions. Cluster #4 is associated with the highest precipitation totals, or areas with the strongest lake-effect precipitation.
UW-RegCM4
click on maps to enlarge






NA-CORDEX
click on maps to enlarge


















Summary of Results
A summary of the results will be added here once the paper is published.
Spatial Evaluation of Lake-Effect Zones
Using MET’s neighborhood analysis tool, we compare the spatial clustering of LEZs in the simulations to the UDel observations. Results are presented in a performance diagram, which is a combination of four performance metrics:
- Frequency bias is the ratio of the number of cluster 4 grid cells in the model projection compared to the observations, regardless of location. A value of 1 = perfect; values >1 indicate the model projected cluster 4 too often across the region, values <1 indicate the model underpredicted cluster 4 across the region.
- Critical success index measures the ratio of the number of times cluster 4 was correctly simulated in the model to the number of times it was either simulated or occurred in the observations. This metric provides information about the amount of spatial overlap over cluster 4s between the model and observations A value of 1 = perfect spatial overlap between the model and observations; a value <1 indicates the model either simulated too many cluster 4 grid cells, too few, or both ; values range from 0 to 1;
- Probability of detection is the fraction of cluster 4 grid cells that were correctly simulated in the model compared to observations. A value of 1 = perfect; values range from 0 to 1.
- Success ratio measures if the model only placed cluster 4 grid cells in locations where they were observed. It is 1 – False Alarm Ratio, or the fraction of events forecasted that didn’t occur. A value of 1 = perfect; values range from 0 to 1.

Summary of Results
A summary of the results will be added here once the paper is published.
Lake-Effect Precipitation Biases
For each cluster of precipitation, we compare the average amount of winter precipitation in the model simulations to the observations. Bias can tell us how much quantitative error is in the precipitation simulations, however, it cannot tell us anything about the quality of the physics in the model. Hence, our evaluation approach also includes the spatial evaluation of lake-effect zones and assessment of the physical processes represented by the lake model used.
We pose that small bias is <10%, and larger biases represent larger errors and uncertainty in the model simulation. The bias for each cluster number is shown in the table. Cluster 1 corresponds to non-lake-effect precipitation and cluster 4 corresponds to the strongest lake-effect precipitation.

Summary of Results
A summary of the results will be added here once the paper is published.